(엔지니어를
위한) 파이썬 시작하기[12]
내용 : pandas 데이터 조작/분석
참조 : https://wikidocs.net/book/7188 (파이썬 완전정복시리즈 2편 pandas dataframe완전정복)
0.시작하며
pandas는
python으로 데이터를 조작하고 분석하는 라이브러리다. 우리가 접하는 데이터들이 대부분 테이블 형태다. 예를 들어 구조해석을 한 결과라고 하면
부재별로 부재력이 나올 것이다. 테이블의 행이 부재번호와 노드로 구성되고 열이 부재력의 종류 즉 축력,전단력 등일 것이다. 업무에서 이런 데이터는
대부분 엑셀로 처리하는 경우가 많다. 행의 갯수가 수백개 정도면 큰 문제가 없지만 수천개 수만개라면 처리하기 쉽지 않다. pandas는 이런 데이터들을
쉽게 처리할 수 있는 다양한 기능들을 제공한다.
1. pandas설치 확인
anaconda를
설치했다면 pandas도 같이 설치되어 있을 것이다. 확인해보기 위해서 anaconda prompt를 띄우고 pip show pandas라고 입력해보자.
|
(base)
D:\dev\pandas>pip show pandas
Name: pandas
Version: 1.3.4
Summary: Powerful data structures for data analysis, time series, and
statistics
Home-page: https://pandas.pydata.org
Author: The Pandas Development Team
Author-email: pandas-dev@python.org
License: BSD-3-Clause
Location: c:\programdata\anaconda3\lib\site-packages
Requires: numpy, python-dateutil, pytz
Required-by: pandasgui, pandastable, pix2tex, seaborn, statsmodels
|
pandas에
관한 정보들을 볼 수 있다. 버번은 1.3.4이고 홈페이지는 https://pandas.pydata.org
그리고 설치되어 있는 디렉토리는 c:\programdata\anaconda3\lib\site-package라는 것을 알 수 있다.
만일
anaconda를 설치하지 않아 pandas가 설치되어 있지 않다면 명령창에서 pip install pandas라고 입력해서 pandas를 설치하면
된다.
2. pandas series 와 dataframe
pandas는
series라는 데이터 형식과 dataframe이라는 데이터 형식이 있다. series는 1차원 dataframe은 2차원으로 이해하면 된다.
두 데이터 형식의 개념을 잘 이해하고 있을 필요가 있다. 대부분 2차원 형태의 dataframe을 사용하지만 1차원인 series를 다뤄야 하는
경우도 종종 있기 때문다.
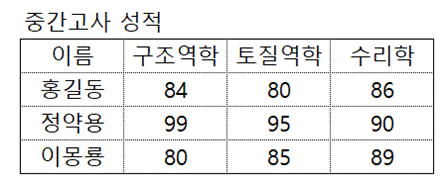
예제로
아래와 같이 중간고사 성적에 대해서 처리하는 작업을 pandas를 이용한다고 가정하겠다. 학생수가 수천명이고 과목수도 많다고 상상해보자.
실습은
jupyter notebook을 이용해서 진행하도록 하겠다. notebook을 사용하면 웹환경이기 때문에 dataframe을 보여줄 때 훨씬 가독성이
높다. 아무 디렉토리나 만들고 그 디렉토리에서 jupyter notebook을 실행하고 새로운 notebook을 하나 만들고 시작하자.
pandas를
사용하기 위해서 import를 하는데 보통은 별칭으로 pd라고 쓴다.
1) pandas Series
series는 1차원 데이터이다. python에서 1차원 데이터는 리스트도
있고 딕셔너리도 있다는 것을 이미 알고 있을 것이다. 예를 들어 [84,99,80]은 리스트다. 구조역학 점수를 리스트로 만들면 이렇게 만들면
된다.
strlst = [84,99,80] 라고 하면 strlst 라는 list가
만들어졌을 것이다. 이것을 pandas series로 만드는 방법은 pd.Series(strlst)라고 pandas의 Series함수를 적용해주는
것이다. Series의 첫글자가 대문자인 것을 주의하자. 소문자로 쓰면 에러가 발생한다. strlst라는 리스트에 pd.Series함수를 적용해서
strsrz라는 변수에 할당하고 출력하도록 했다.
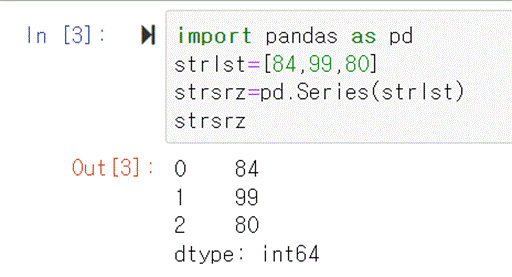
Out을 보면 리스트에 없던 것이 보인다. 값 앞에 0 , 1, 2 가 붙어
있는 것을 알 수 있다. 이것을 인덱스라고 한다. Series는 인덱스를 가지고 있다는 것을 기억하자. dataframe역시 인덱스를 가지고 있다.
인덱스는 데이터를 다루는데 있어 중요한 요소가 된다.
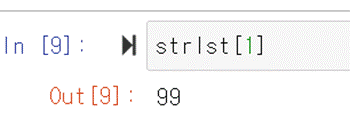
인덱스는 값에 접근할 때 쓰인다. 예를 들어 strsrz의 인덱스 1인 값을
알고 싶다면 strsrz[1]으로 접근할 수 있다. 이 개념은 리스트에 접근할 때와 큰 차이는 없다.
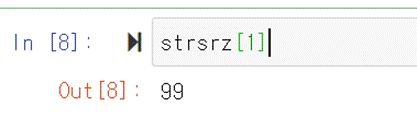
strlst[1]도 같은 결과라는 것을 알 수 있다. 하지만 pandas
Series의 index는 사용자가 원하는 것으로 넣을 수 있다는 것이 list와의 차이점이다.
아래와 같이 Series를 만들면서 index를 지정할 수 있다.

index를 지정하지 않으면 자동으로 0부터 인덱스가 생성되는 것이고 인덱스를
지정하면 그대로 인덱스가 생성된다. 문자로도 가능하는 것을 알 수 있다. 당연히 값에 접근할 때도 문자열 인덱스를 이용해서 접근할 수 있다. 예를
들어 홍길동의 토질역학 점수를 알고 싶다면 geosrz[‘홍길동’]라고 하면 된다.
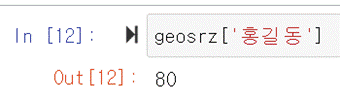
이렇게 문자열로 값에 접근하는 방식은 딕셔너리와 비슷하다는 것을 알 수 있을
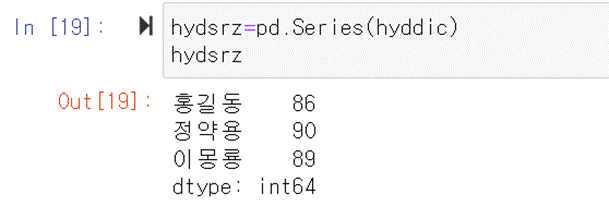
것이다. 딕셔너리는 key와 value의 쌍으로 이루어져 있다는 것을 기억하자. hyddic={'홍길동':86,'정약용':90, '이몽룡':89}

Series와 dictionary는 유사한 점이 많다. 그래서 딕셔너리를
Series로 만드는 것은 매우 간단하다. index를 별도로 지정해줄 필요가 없다. 딕셔너리에는 이미 key값이 있기 때문이다.
시리즈의 index와 value를 별도로 취할 수 있다. index목록은
index라는 속성을 값 목록은 values라는 속성을 이용한다. hydsrz의 index와 값들을 뽑아보자.


시리즈의 특징 중의 하나는 바로 시리즈에 이름을 부여할 수 있다는 것이다.
변수명 hydsrz 이것 말고 문자열로 이름을 지정할 수 있다는 것이다.
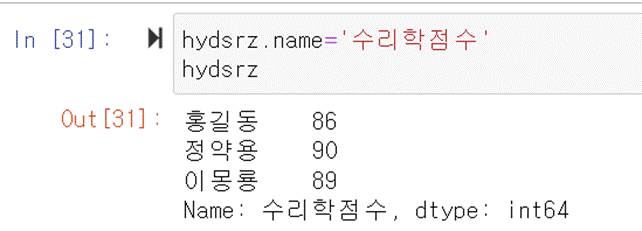
예를 들어 hydsrz에 ‘수리학점수’라는 이름을 지정하려면 아래와 같이
하면 된다.
hydsrz.name='수리학점수'
hydsrz를 출력해보면 이름이 ‘수리학점수’ 라는 것을 보여준다.
인덱스에도 이름을 줄 수 있다.

Series의 인덱스를 변경하려면 index를 직접 지정해주면 된다. 이름
앞에 숫자를 붙인 것으로 수정했다.

2) pandas Dataframe
앞에서
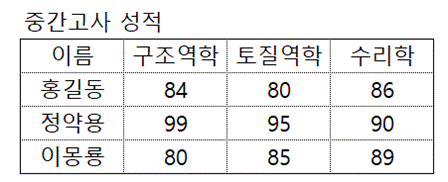
pandas의 Series에 대해서 알아봤다. 이제 2차원의 Daraframe에 대해서 알아보자. 앞의 중간고사 점수를 다시한번 보자.
여기에는
4개의 행과 4개의 열이 있다. 하지만 첫행은 과목명을 나타내기 위한 행이다. 그리고 첫 열은 이름을 나타내는 행이다. 순수한 데이터는 3개의
행과 3개의 열이라고 할 수 있다. 이것을 pandas Dataframe으로 만들어보자.
여러가지
방법이 있지만 우선 딕셔너리를 이용하는 방법이다. 딕셔너리의 key가 열의 이름이되고 리스트가 열의 값이 되는 개념이다. 우선 middic이라는
딕셔너리를 만든 후에 pd.DaraFrame(middic)으로 pandas DataFrame을 만들었다. notebook의 장점은
DataFrame의 모양을 테이블로 보기 좋게 보여준다는 것이다.

자
이제 첫 DataFrame을 만들었다. 순수한 값만 넣었고 이름을 DataFrame에 포함시키지 않았다. 이유는 이렇다. 현재 이
DataFrame에는 순수한 값 데이터만 들어 있다. index는 0,1,2이런식으로 되어 있다. 그런데 우리가 정약용의 점수를 알고 싶다면 정약용의
순서(index)인 1을 알아야 한다. 그래서 앞의 Series에서처럼 index를 이름으로 지정해주고 싶은 것이다. index를 이름으로 해놓으면
이름으로 데이터에 접근이 가능하기 때문에 훨씬 편할 것이다.
Series에서
했던 것처럼 index를 지정해주면 된다.
middf.index=['홍길동','정약용','이몽룡']

이
DataFrame의 행 index는 ‘홍길동’, ‘정약용’,’이몽룡’이다. 마찬가지로 열 인덱스는 ‘구조역학’, ‘토질역학’, ‘수리학’이다.
열 인덱스는 index라고 부르지 않고 columns라고 부른다. index와 columns를 출력해보면 아래와 같다.

그러면
홍길동의 점수를 알고 싶다면 middf[‘홍길동’]이렇게 하면 될까? 아니다. key 에러가 발생한다. key에러는 그런 key가 없다는 것이다.
기본적으로 DataFrame은 열 우선이라고 생각하는 것이 편하다. 그래서 middf[‘수리학’]은 가능하다.

그렇다면
홍길동의 점수를 알아보려면 어떻게 해야할까? 여기서부터는 DataFrame 클래스의 여러가지 함수들을 알아보도록 하겠다. 원하는 기능이 있다면
구글에서 찾아보면 된다. 예를 들어서 홍길동의 점수를 알고 싶다면 검색을 이렇게 하면 될 것이다. pandas get row by index 검색결과를
몇군데 찾아보면 loc함수가 있다는 것을 알 수 있을 것이다. DataFrame의 기본적인 개념을 알고 있다면 구글링으로 자신이 원하는 작업을
하는 방법을 찾아보기를 권장한다.
-
loc[rowindex, columnindex]
loc함수는 행과 열 index를 이용해서 해당 값을 취할 수 있다.
홍길동의 세 과목 점수를 알고 싶다면 middf.loc[‘홍길동’]라고 입력하면
되고 홍길동의 수리학 점수를 알고 싶다면 middf.loc[‘홍길동’,’수리학’]이렇게 입력하면 된다.


-
iloc[rowindex, columnindex]
loc이 행과 열의 이름을 이용해서 선택했다면 iloc은 행번호,열번호를
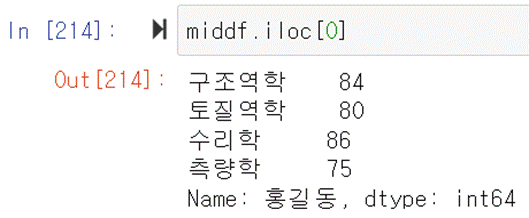
이용해서 dataframe의 일부를 선택할 수 있다. 홍길동의 점수를 알고 싶다면 홍길동의 행번호인 0을 이용해서 iloc으로 선택가능하다.
middf.iloc[0]
loc와 iloc모두 행과 열을 지정할 수 있다. 행과 열을 지정할 때
:를 이용해서 slicing이 가능하다. 예를 들어 홍길동과 정약용의 토질역학과 수리학 점수만을 취하려면 이렇게 하면 된다. 슬라이싱에서 : 뒤의
숫자는 포함되지 않는다는 것을 기억하자.
middf.iloc[0:2,1:3]

iloc이 아닌 loc을 사용해서도 같은 방법으로 작동한다. iloc과 달리
:뒤쪽도 포함되는 것을 알 수 있다.
middf.loc['홍길동':'정약용','토질역학':'수리학']

-
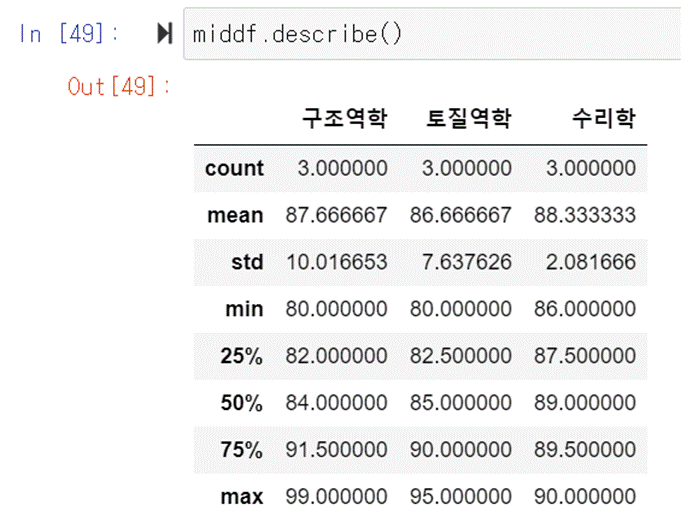
describe()
데이터 프레임이 가지고 있는 숫자들의 개수, 평균,표준편차, 최대값, 최소값
등 개략적인 통계값을 보여주는 간단한 기능이다.
-
column 추가
측량학점수를 추가하려면 어떻게 해야할까? column을 추가하면 될 것이다.
column을 추가하는 방법은 새로운 column이름과 값을 리스트로 입력해주면 된다.

만약 index개수와 다른 개수의 값을 추가하면 어떻게
될까? 상하수도를 추가하는데 4개의 값을 입력해보자.

에러가 발생한다. 에러메시지는 다음과 같다.
ValueError: Length of
values (4) does not match length of index (3)
인덱스는 3개인데 값이 4개를 할당하려고 했다는 것이다.
개수가 적어도 당연히 에러가 발생한다.
-
row 추가
이번에는 학생을 한명 추가해보자. 뽀로로 학생을 추가할
것이다. 각 과목의 점수는 구조역학 87, 토질역학 83, 수리학 75, 측량학 90이다. 기억해야할 것이 DataFrame에 행을 하나 추가하기
위해서는 추가할 내용을 새로운 DataFrame으로 만들어서 추가해야 한다는 것이다.
그래서 뽀로로의 점수를 새로운 dataframe으로
만든다. 변수명은 dftemp라고 하겠다. 데이터를 column이름과 점수로 이루어진 딕셔너리 형태로 주고, 인덱스를 정해준다. 여기서 인덱스가
하나지만 리스트 형태로 줘야한다는 것을 기억하자.
dftemp=pd.DataFrame({'구조역학':87,
'토질역학': 83, '수리학': 75, '측량학': 90},index=['뽀로로'])

자 이제 새로운 dataframe을 원래의
dataframe에 추가하자. concat함수를 적용한다. 합쳐진 dataframe을 middf1로 지정하겠다. 주의할 점은
middf와 dftemp를 [ ]안에 넣어야 한다는 것이다.
middf1=pd.concat([middf,dftemp])

-
row 삭제
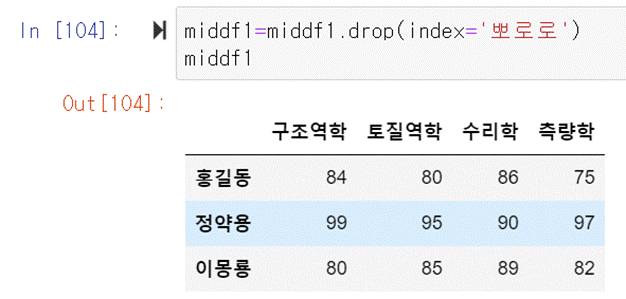
행이나 열을 삭제할 때는 drop함수를 이용한다. 뽀로로의 성적을 삭제하기
위해서는 index를 뽀로로로 지정해주면 된다. middf1=middf1.drop(index=’뽀로로’)
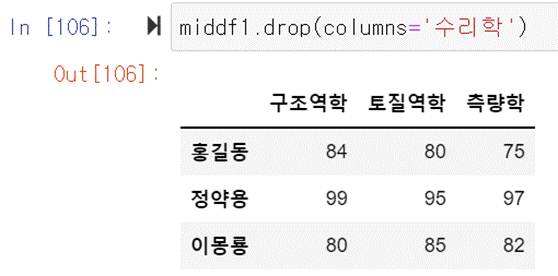
컬럽을 삭제해보자. 마찬가지로 drop함수를 사용한다. 수리학 컬럼을 삭제하기
위해서 columns=’수리학’을 지정해주면 된다. 행은 index 열은 columns라는 것을 기억하자. column이 아니라 columns다.
수리학이 삭제된 것을 확인할 수 있다. middf1에서 수리학을 삭제만 했고 middf1에 할당하지 않았기 때문에 middf1은 아직 수리학이
삭제되지 않았다는 것을 기억하자.
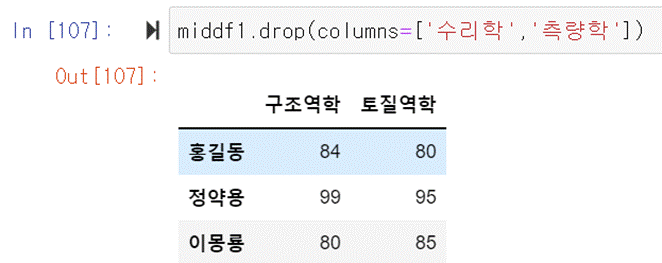
수리학과 측량학을 모두 삭제하려면 columns=[‘수리학’,’측량학’]이라고
지정해주면 된다.
-
column 합, 평균, max, min
column의 합,평균,max,min은 middf1.sum(),
mean(), max(), min()의 함수로 구할 수 있다.

이렇게 구해진 값들의 형식은 무엇일까? type함수를 이용해서 알아보면
Series라는 것을 알 수 있다.

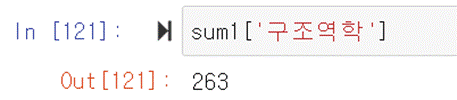
이 데이터 형이 Series라는 것은 수학의 합계를 알고 싶다면
sum[‘수학’]이라고 하면 된다는 것을 알 수 있다.
-
row 합, 평균, max, min
앞에서 살펴본 column의 sum,mean 등과 비슷하다. 단지
sum(axis=1)이라는 것만 다르다. axis=0은 컬럼, axis=1은 행이라는 것을 기억하자. 사실 앞의 column에 대한 sum등은
axis=0이 생략된 것이다. 즉 default가 열이라는 것이다.

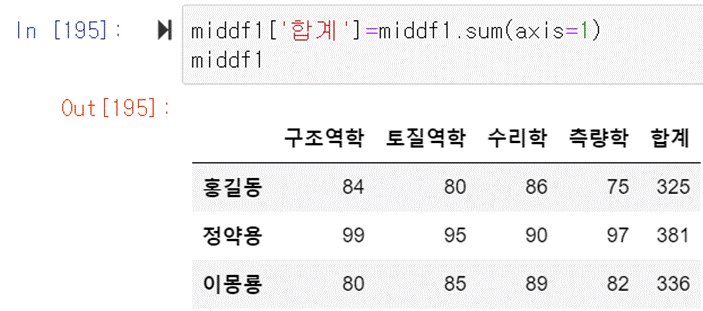
점수합을 column으로 추가하고 싶다면 middf1[‘합계’]=middf1.sum(axis=1)이라고
해주면 된다.
같은 방법으로 평균값을 추가해보자. 그냥 mean(axis=1)을 적용하면
합계까지 포함된 평균값이 산정된다. 따라서 구조역학부터 측량학 컬럼까지만 선택해서 mean을 적용해야 한다.

일부 컬럼만 선택하는 방법을 각 컬럼이름을 나열해주면 된다.
middf1[‘평균’]=middf1[[‘구조역학’,’토질역학’,’수리학’,’측량학’]].mean(axis=1)
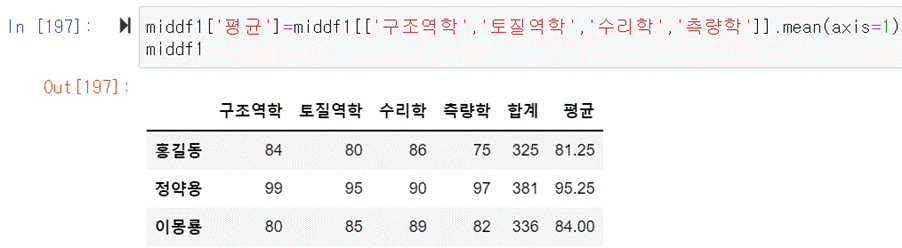
-
column에 수식 적용하기(apply)
이미 합계를 구해서 합계 칼럼을 만들었으니 평균은 그 합계를 과목 수인
4로 나누면 될 것이다.이와 같이 어떤 칼럼에 수식을 적용하기 위해서 apply함수를 쓴다. lambda 익명함수로 x를 인자로 받아서 x에 대해서
할 연산을 정의한다.

-
column연산
앞의 apply와 달리 컬럼간의 연산을 정의할 수 있다. 물론 일정한 값을
더하거나 빼거나 곱할 수도 있다. 간단한 연산은 column연산을 이용하고 복잡한 연산은 apply를 이용한다고 보면 된다.
예를 들어 수리학 점수에 일괄적으로 5점의 가점을 준다고 생각해보자.

수리학 점수가 변한 것을 알 수 있다. 주의할 점은 합계와 평균은 변하지
않았다는 것이다.
이렇게 컬럼에 대해서 add(), sub(), mul(), div(),
mod(), pow() 등의 함수를 쓸 수 있다. 각각 더하기, 빼기, 곱하기, 나누기, 나머지, 제곱의 기능을 가지고 있다.
실제로 그럴 일은 없지만 구조역학 점수에서 토질역학점수를 빼보자.
middf1['토질역학'].sub(middf1['수리학'])

sub()함수를 사용하지 않고 +, -, *, / 연산자를 사용할 수도 있다.
middf1['토질역학']-middf1['수리학']

-
dataframe 정렬(sort)
dataframe을 정렬하는 함수는 sort_index와
sort_values가 있다. sort_index는 index나 columns를 기준으로 정렬하는 것이고 sort_values는 값들을 기준으로
정렬한다.
앞의 dataframe을 정렬해보자. 사람이름으로 정렬하려면
sort_index를 이용한다. ()안에 아무것도 없는 것은 default로 오름차순으로 정렬하는 것을 의미한다.
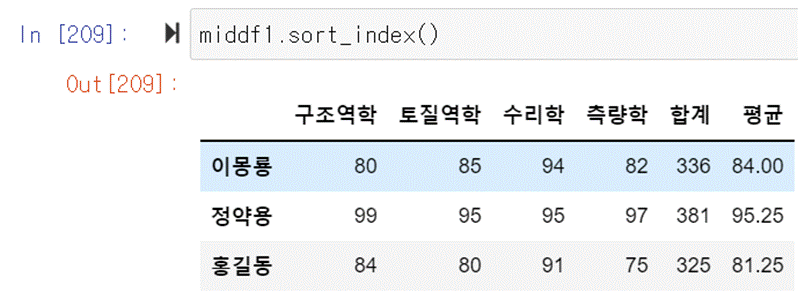
내림차순으로 정렬하기 위해서는 ()안에 ascending=False를
입력해준다.

이번에는 열이름을 기준으로 정렬을 해보겠다. ()안에 axis=1을 입력해주면
된다. 행의 순서를 정렬하는 것에는 default로 axis=0이 적용되었다는 것을 알 수 있다.
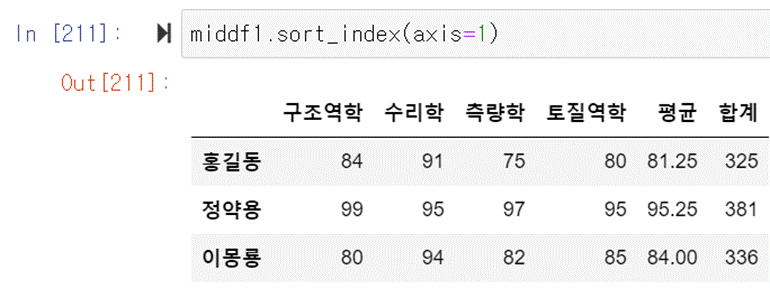
3. dataframe 파일 입출력
pandas로
데이터를 다루려면 데이터를 읽어오고 쓸 수 있어야 한다. 콤마로 구분된 파일 CSV파일을 많이 쓴다. 이 포맷은 엑셀에서도 열린다. CSV파일은
텍스트파일이기 때문에 확인도 쉽다. csv파일로 쓰고 읽고 하는 것을 해보자.
pandas에서는
to_csv()함수와 read_csv()함수 두개를 지원한다.
1) csv 파일로 출력하기
위에서
만든 중간고사 점수를 csv파일로 저장해보자. 데이터프레임에 대해서 to_csv함수를 실행하면 된다. 인자로는 파일명을 준다. .은 현재 디렉토리라는
뜻으로 jupyter notebook을 실행한 디렉토리다.
middf1.to_csv(“./middf1.csv”)
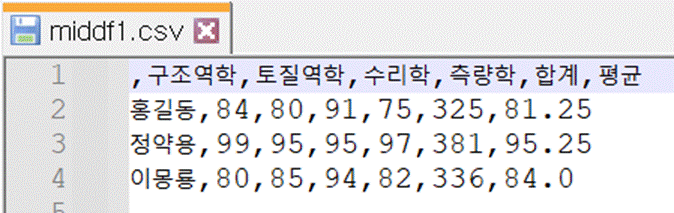
csv을
텍스트에디터로 열어서 확인해보면 제대로 만들어진 것을 확인할 수 있다. 첫줄은 columns 즉 열 이름들이다. 그 아래줄부터 처음에
index그리고 각 과목의 점수와 합계,평균이 출력되었다. 첫줄의 맨 앞이 ,로 시작한 이유는 index에 이름을 지정하지 않았기 때문이다.
index와
column에 이름을 지정하려면 아래와 같이 하면 된다.
middf1.index.name="이름"
middf1.columns.name="과목명"
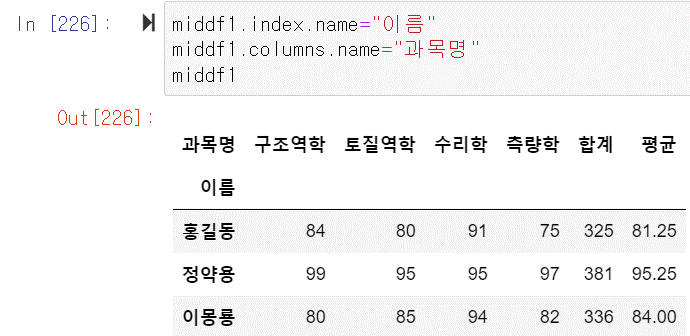
다시
to_csv를 해보면 이름이 추가된 것을 확인할 수 있다.
|
이름,구조역학,토질역학,수리학,측량학,합계,평균
홍길동,84,80,91,75,325,81.25
정약용,99,95,95,97,381,95.25
이몽룡,80,85,94,82,336,84.0
|
2) csv 파일로부터 읽기
이번에는
csv파일을 읽어서 dataframe을 만드는 것을 해보자. 앞에서 만든 파일을 그대로 읽어서 middf2에 저장하겠다.
middf2
= pd.read_csv(“./middf1.csv”)

이전의
middf1과 다른 것을 알 수 있다. 인덱스가 0,1,2로 되었고 이름은 컬럼으로 인식된 것을 알 수 있다. 0,1,2 인덱스 대신 이름을
index로 지정하려면 index_col을 지정해주면 된다.
middf2
= pd.read_csv("./middf1.csv",index_col="이름")

4. 마무리
이번
시간에는 pandas의 dataframe을 다루어보았다. dataframe의 개념만 파악하는 수준었다. 실제로 더 많은 기능이 있으니 자신이 필요한
기능은 검색을 통해서 알아본다음에 사용하는 것을 권장한다.
dataframe이
엑셀과 다른 점은 많다. 엑셀에서는 순수한 데이터만 있는 것이 아니라 데이터들을 분석한 결과들도 같은 시트에 저장하는 경우가 많다. 엑셀에서는
계산결과를 셀에 넣어야 하기 때문에 그렇지만 python pandas 코딩에서는 계산 결과를 변수에 넣기 때문에 데이터 따로 분석결과 따로 관리할
수 있다.
이번
예제는 이해를 돕기 위해서 몇명 안되는 사람들의 과목점수를 다루었다. 예를 들어서 지진관측결과는 수천 수만개의 시계열 데이터가 될 것이다. 그런
데이터를 dataframe에 넣어 놓고 분석할 때 엑셀보다는 훨씬 편하고 안정적일 것이다.
-끝-



 0 분
0 분 30 분
30 분