(ПЃСіДЯОюИІ
РЇЧб) ЦФРЬНу НУРлЧЯБт[5]
ГЛПы : ЦФРЯ РдУтЗТ
ТќСЖ : https://wikidocs.net/26
https://docs.python.org/ko/3/tutorial/inputoutput.html#reading-and-writing-files
0.НУРлЧЯИч
ЦФПЁМ
ЧСЗЮБзЗЅРК РдЗТЁцАшЛъЁцУтЗТРИЗЮ БИКаЧв Мі РжДйАэ ЧпДТЕЅ ЦФРЯРК РдЗТРИЗЮЕЕ ОВРЬАэ УтЗТРИЗЮЕЕ ОВРЮДй. КИХы ПЃСіДЯОюЕщРК ЧбАГРЧ ЧСЗЮБзЗЅИИРИЗЮ РЯЧЯСі
ОЪДТДй ОюЖВ ЧСЗЮБзЗЅРЛ ЕЙЗСМ ГЊПТ АсАњ(ЦФРЯ)РЛ РаОюМ АшЛъРЛ ЧЯАэ Бз АсАњИІ УтЗТРЛ ЧбДй.
БзЗЁМ
ЦФРЯРЛ РаАэ ОВДТ ЙцЙ§ПЁ ДыЧиМ Рп ОЫАэ РжРЛ ЧЪПфАЁ РжДй. ПЉБтМ ДйЗчДТ АЧ ХиНКЦЎ ЦФРЯРЬДй. ЦФРЬНуРИЗЮ ПЂМПlЦФРЯЕЕ ИИЕщАэ, РаАэ, МіСЄЧв
Мі РжДй. ОЦЙЋЗЁЕЕ ПЃСіДЯОюИЕ НЧЙЋПЁМ ПЂМПЦФРЯРЛ ИЙРЬ ОВБт ЖЇЙЎПЁ ПЂМПЦФРЯРЛ ДйЗчДТ АЧ ГЊСпПЁ ЕћЗЮ ЧЯАэ РЬЙјПЁДТ ХиНКЦЎ ЦФРЯ ДйЗчДТ АЭИИ СјЧрЧЯАкДй.
1. ЦФРЯ РаБт
ЦФРЯРЛ
РаДТ ЙцЙ§РК РЯДм ЦФРЯРЛ ПАэ БзДйРН РаБт ЧдМіИІ ЛчПыЧбДй. ЦФРЯРЛ ПЉДТ ЧдМіДТ ОЦЗЁПЭ ААДй.
|
f = open("C:/doit/ЛѕЦФРЯ.txt", 'r')
|
open()ОШПЁ
ЦФРЯРЧ full pathИэ(Е№ЗКХфИЎ+ЦФРЯИэ)Ањ ЁЎrЁЏРЛ РдЗТЧиМ РаБт РЇЧи ПЌДйДТ АЩ ОЫЗССжИщ ЕШДй. openЧдМіРЧ АсАњДТ fПЁ РдЗТЕЧАэ ОеРИЗЮ
fИІ РЬПыЧиМ РаБт АќЗУ БтДЩРЛ МіЧрЧбДй. ПБтИИ ЧЯАэ ОЦСї РаСіДТ ОЪОвДй.
ЦФРЯРЛ
ПИщ ДчПЌШї ДнОЦОп ЧбДй. ДйДТ ИэЗЩРК ОЦЗЁПЭ ААДй.
fДТ
ЦФРЯРЛ ПРЧТЧв ЖЇ СЄЧиСи Йй РжДй. ЦФРЯРЧ ГЛПыРЛ РаДТ ИэЗЩЕщРК openАњ closeЛчРЬПЁ ЙшФЁЧЯИщ ЕШДй.
РаДТ
ЙцЙ§РК ИюАЁСіАЁ РжДй. ТїРЬСЁРЛ ОЫОЦКИАэ АЁРк.
1) f.readline() Чб СйОП РаДТДй. Ёц ПЉЗЏСйРЛ РаБт РЇЧи
forЙЎРИЗЮ ЙнКЙЧЪПф. ЦФРЯ РќУМРЧ ГЛПыРЛ ЧЯГЊРЧ КЏМіПЁ ГжБт РЇЧиМДТ ИЎНКЦЎПЁ УпАЁИІ ЧиОп ЧбДй.
2) f.readlines() РќУМИІ РаОюМ ЧЯГЊРЧ ИЎНКЦЎЗЮ ИИЕчДй.
ИЎНКЦЎРЧ ПфМвЕщРК АЂ СйЕщРЬДй.
Ёц АЂ СйКАЗЮ РлОїРЛ ЧЯБт РЇЧиМ forЙЎРИЗЮ ЙнКЙЧбДй.
3) f.read() РќУМИІ РаОюМ ЧЯГЊРЧ ЙЎРкПЗЮ ИИЕчДй.
Ёц АЂ СйКАЗЮ РлОїРЛ ЧЯБт РЇЧиМДТ СйЗЮ ГЊДВОп ЧбДй.
РаРЛ
ЦФРЯРЬ ОюЖВ АЭРЬГФПЁ ЕћЖѓ ОюДР ЙцЙ§РЛ ОВДТ АЭРЬ АЁРх ШПРВРћРЯСі ЦЧДмЧиМ МБХУЧиОп ЧЯСіИИ, СйКАЗЮ РлОїРЛ ЧбДйИщ 2ЙјТА ЙцЙ§РЬ АЁРх ЦэЧв АЭРЬДй.
ПЙИІ
ЕщОю БИСЖЧиМЎ ЧСЗЮБзЗЅРЧ ЧиМЎАсАњ ЦФРЯРЬ ОЦЗЁПЭ ААДйАэ ЧЯРк. АЂ ГыЕхРЧ УГСќАЊРЬДй.
|
JOINT
UX
UY
UZ RX
RY RZ
101 351.754000 351.754000 351.754000 8178.447 .000000 .000000
102 259.268000 259.268000 259.268000 16356.890 .000000 .000000
103 259.268000 259.268000 259.268000 16356.890 .000000 .000000
104 259.268000 259.268000 259.268000 16356.890 .000000 .000000
105 243.063000 243.063000 243.063000 14312.280 .000000 .000000
|
ЦФРЯРЬИЇРЬ
result.txtДй. РЬ ЦФРЯРЧ РЇФЁДТ d:\dev\python\result.txtДй. РЬ ЦФРЯРЛ РаОюМ АЂ ГыЕхРЧ КЏРЇАЊРЛ БИЧЯДТ БтДЩРЛ ИИЕщАэРк
ЧбДй.
ЕЮЙјТА
ЙцЙ§ readlines()РЛ НсМ РаОюКИРк. ХиНКЦЎПЁЕ№ХЭИІ ПОю ОЦЗЁРЧ ФкЕхИІ РдЗТЧЯРк.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
print(result)
|
ЧСЗЮБзЗЅРЧ
ГЛПыРК ЦФРЯРЛ open()РИЗЮ ПАэ f.readlines()ЗЮ РаОюМ resultЖѓДТ КЏМіПЁ ГжАэ ЦФРЯРЛ ДнАэ, ИЖСіИЗРИЗЮ printЗЮ УтЗТЧЯЖѓДТ
ГЛПыРЬДй.
readresult.pyЖѓДТ
РЬИЇРИЗЮ РњРхЧбДйРН. НЧЧрНУХАИщ ОЦЗЁПЭ ААРК АсАњИІ КМ Мі РжДй.

КгРК
Лі ПјЕщРЛ СжИёЧЯРк. СІРЯ УГРНПЁ [ЗЮ НУРлЧпАэ ИЖСіИЗПЁ ]ЗЮ ГЁГЕДй. [ЗЮ НУРлЧЯАэ ]ЗЮ ГЁГЊДТ АЧ ИЎНКЦЎЖѓДТ ЖцРЬДй. ИЎНКЦЎ ОШПЁ ЁЎ~ЁЏРЮ
ЙЎРкПЕщРЬ ,ЗЮ БИКаЕЧОю ЕщОюАЁ РжДй. Ся ЧбСйРЬ Чб ЙЎРкПЗЮ ЕщОюАЁ РжДТ АЭРЬДй. БзЗБЕЅ ЙЎРкПРЧ ИЖСіИЗРЛ КИИщ ЁЎ\nЁЏРЬ РжДй. ЙЎРкП ОШПЁ
РжДТ \nРК ЛѕЗЮПю ЖѓРЮРЧ Ся СйЙйВоРЧ ЖцРЬДй. readlinesЗЮ РаРИИщ ЙЎРкПРЧ ИЧ ГЁПЁ СйЙйВоЙЎРкАЁ ЦїЧдЕШДйДТ АЭРЛ ОЫ Мі РжДй.
РЬЙјПЁДТ
resultЖѓДТ listПЁ ЕщОюРжДТ АЂ ЙЎРкПРЛ УтЗТЧиКИРк. ОеПЁМДТ resultЖѓДТ listИІ ХыТАЗЮ УтЗТЧпДТЕЅ РЬЙјПЁДТ АЂ СйРЛ УтЗТЧЯЗСАэ
ЧбДй. ИЎНКЦЎ ОШПЁ РжДТ ПфМвЕщПЁ ДыЧиМ ОюЖВ ЧрРЇИІ ЧЯЗСИщ forЙЎРИЗЮ ЙнКЙЧЯИщ ЕШДй.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
for iresult in result:
print(iresult)
|
ОеПЁМ
АјКЮЧб forЙЎРЛ НшДй. ЕщПЉОВБт СжРЧЧЯАэ ИЎНКЦЎ ОШРЧ АЂ ПфМвИІ iresultЖѓДТ КЏМіПЁ ГжАэ БзАЭРЛ printЙЎРИЗЮ УтЗТЧпДй. РаОњДј АЩ БзДыЗЮ
УтЗТЧЯДТ ЧСЗЮБзЗЅРЬДй.
АсАњДТ
ОЦЗЁПЭ ААДй.

ПјКЛЦФРЯАњ
ДйИЃДй. Сй ЛчРЬПЁ Кѓ СйРЬ ЧЯГЊОП УпАЁЕЧОњДй. Пж БзЗВБю? ОеПЁМ ИЛЧб ЙЎРкП ИЖСіИЗРЧ ЁЎ\nЁЏЖЇЙЎРЬДй. printЙЎ РкУМАЁ УтЗТЧЯАэ ЧбСй ОЦЗЁЗЮ
ГЛЗСАЁДТ БтДЩРЬ РжДТЕЅ ЙЎРкП ОШПЁ ЁЎ\nЁЏЖЇЙЎПЁ ЧбСй Дѕ ГЛЗСАЃ АЭРЬДй.
strip()
БзЗЁМ
ЁЎ\nЁЏРЛ СІАХИІ ЧиСжДТ АЭРЬ ССДй. ЦФРЬНуПЁДТ ЙЎРкПРЧ Ое ЕкИІ СЄИЎЧиСжДТ БтДЩРЬ РжДй. ЙйЗЮ strip()РЬДй. ЛчПыЙ§РК АЃДмЧЯДй. ЙЎРкППЁ
.strip()ЧиСжИщ ЕШДй.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
for iresult in result:
print(iresult.strip())
|
iresult.strip()
Ёц readresult1.pyПЁМ РЬАЭИИ ЙйВхДй. НЧЧрАсАњДТ ОЦЗЁПЭ ААДй.

Сй
ЛчРЬПЁ Кѓ СйРЬ РжДј АЭРЬ Кѓ СйРЬ ОјОюСГДй. ЁЎ\nЁЏРЬ СІАХ ЕШ АЭРЬДй.
БзЗБЕЅ
ПјКЛАњ СЛ ДйИЃДй. ИЧОеРЧ АјЙщЕщРЬ ОјОюСГДй. БзЗИДй strip()БтДЩРК ОеЕк АјЙщРЛ ОјОжСжДТ БтДЩРЬБт ЖЇЙЎПЁ ОеРЧ АјЙщЕщРЬ СіПіСГДй.
split()
РЬСІ
АЂ СйРЧ ЕЅРЬХЭЕщРЛ ТЩАГМ ИЎНКЦЎЗЮ ИИЕщОюКИРк. РЬЗЁОп АЂ АЊЕщРЛ РЬПыЧв Мі РжДй. РЬ БтДЩРК ИЛБзДыЗЮ split()БтДЩРЛ ОВИщ ЕШДй.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
for iresult in result:
isplt=iresult.split()
print(isplt)
|
readresult2.pyПЭ
ДйИЅ СЁРК iresultИІ split()ЧпДйДТ АЭРЬДй. splitЧб АсАњИІ ispltПЁ ГжОњДй. splitРЛ ЧЯИщ ИЎНКЦЎАЁ ИИЕщОюСјДй. ЕћЖѓМ
splitЧб АсАњАЁ ЕщОюАЁДТ ispltДТ ИЎНКЦЎДй. РЬАЭРЛ printЙЎРИЗЮ УтЗТЧпДй.

splitБтДЩРК
БтКЛРћРИЗЮ АјЙщРЛ БтСиРИЗЮ ГЊДЋДй. ЙЎРкП ЕкПЁ .split()РЬЗИАд РдЗТЧиСжИщ АјЙщРИЗЮ ГЊДЉАэ split(ЁЎ,ЁЏ) РЬЗИАд РдЗТЧЯИщ ЁЎ,ЁЏИІ БтСиРИЗЮ
ГЊДЋДй.
ЁЎ1,2,3ЁЏ.split(ЁЎ,ЁЏ)
Ёц АсАњДТ [ЁЎ1ЁЏ, ЁЏ2ЁЏ, ЁЏ3ЁЏ]РЬЗИАд ЕШДй.
БтОяЧиОп
Чв АЭРК splitАсАњАЁ [ПЭ ]ЗЮ АЈНзПЉСј ИЎНКЦЎЗЮ ЕЙЗССиДйДТ АЭРЬДй. БзИЎАэ ЙЎРкПРЛ ТЩАКБт ЖЇЙЎПЁ ДчПЌШї Бз АсАњЕЕ ЙЎРкПРЧ ИЎНКЦЎЖѓДТ АЭРЬДй.
ПьИЎДТ
РЬ ЙЎРкПРЛ М§РкЗЮ ЙйВуОп АшЛъПЁ НсИдРЛ Мі РжДй. БзЗЁМ ЧќКЏШЏРЛ РЬПыЧбДй. УЙ НУАЃПЁ ЧќКЏШЏПЁ ДыЧиМ АјКЮЧб Йй РжДй. int(),
float(). АЂАЂ ЙЎРкПРЛ СЄМіЗЮ ЙйВйАэ НЧМіЗЮ ЙйВйДТ ЧдМіДй.
УЙЙјТА
Сй ['JOINT', 'UX', 'UY', 'UZ', 'RX', 'RY', 'RZ'] ДТ ЧќКЏШЏРЬ ЧЪПф ОјДй. ЕЮЙјТА СйКЮХЭ ЧќКЏШЏРЛ ЧиКИРк. РЇРЧ ФкЕхПЁМ
forЙЎРЧ ДыЛѓРЛ ЕЮЙјТА СйКЮХЭ ГЁБюСіЗЮ ЧЯБт РЇЧиМ for iresult in result[1:]:
РЬЗИАд МіСЄЧпДй. resultАЁ ИЎНКЦЎРЮЕЅ БзСпПЁМ ЕЮЙјТА(index=1)КЮХЭ ИЖСіИЗБюСіРЧ ЖцРЮ [1:]ИІ КйПДДй.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
for iresult in result[1:]:
isplt=iresult.split()
inode=int(isplt[0])
idisp=list(map(float,isplt[1:]))
inodedisp=[inode]+idisp
print(inodedisp)
|
РЇ
ФкЕхИІ readresult4.pyЗЮ РњРхЧЯАэ НЧЧрЧЯИщ ОЦЗЁПЭ ААРК АсАњИІ КМ Мі РжДй.
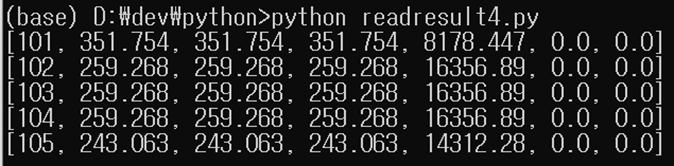
ИЧ
ОеРЧ nodeДТ СЄМіЧќ БзДйРН UX, UY, UZ, RX, RY, RZДТ НЧМіЧќРИЗЮ КЏШЏЧпДй.
inode=int(isplt[0])
Ёч ispltДТ splitЧб АсАњ Ся listДй БзАЭРЧ УГРНПфМвИІ УыЧЯАэ isplt[0] БзАЭПЁ intЧдМіИІ РћПыЧпДй. СЄМіЗЮ КЏШЏЧб АЭ. БзАЭРЛ
inodeПЁ ГжОњДй.
idisp=list(map(float,isplt[1:]))
Ёч СЛ КЙРтЧбЕЅ mapЧдМіИІ ОЫОЦОп ЧбДй.
list(map(ЧдМіИэ,list)) :
ИЪЧдМі ЛчПыЙ§РК ПоТЪАњ ААДй. listРЧ АЂ ПфМвПЁ ЧдМіИІ РћПыЧиМ Бз АсАњИІ ИЎНКЦЎЗЮ ЕЙЗССиДй.
ПЙИІ ЕщОюКИРк. python
РЮХЭЧСИЎХЭИІ ФбАэ ХзНКЦЎЧиКИРк.
|
(base) D:\dev\python>python
Python 3.9.7 (default, Sep 16 2021, 16:59:28) [MSC v.1916 64 bit (AMD64)] ::
Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more
information.
>>> list(map(int,['1','2']))
[1, 2]
>>>
|
[ЁЎ1ЁЏ, ЁЎ2ЁЏ]ЖѓДТ ИЎНКЦЎРЧ
АЂ ПфМвПЁ intЧдМіИІ РћПыЧиМ БзАЭРЛ ИЎНКЦЎЗЮ ИИЕщОю ЕЙЗССиДй. АсАњАЁ [1,2]ЗЮ ГЊПТ АЩ КМ Мі РжДй.
idisp=list(map(float,isplt[1:]))
Ёч БзЗЁМ РЬ ЙЎРхРК ispltРЧ ЕЮЙјТАКЮХЭ (УЙЙјТАДТ nodeЖѓМ ЕћЗЮ СЄМіЗЮ КЏШЏЧпОњДй) ИЖСіИЗБюСіИІ НЧМіЧќРИЗЮ КЏШЏ(float)ЧиМ ИЎНКЦЎЗЮ
ИИЕщОю idispПЁ РњРхЧпДй.
Рк РЬСІ inodeПЁДТ ГыЕхЙјШЃ
СЄМіАЁ idispПЁДТ КЏРЇ НЧМіИЎНКЦЎАЁ ЕщОюРжДй.
ЕЮАГИІ ДѕЧиМ ЧЯГЊРЧ ИЎНКЦЎЗЮ
ИИЕщБт РЇЧиМ +ПЌЛъРкИІ ОВИщ ЕШДй.
ИЎНКЦЎ ДѕЧЯБт(ПЌАсЧЯБт)
inode+idisp РЬЗИАд
ЧЯИщ ПЁЗЏАЁ ЖсДй. inodeДТ БзГЩ СЄМіАЊРЬАэ idispДТ ИЎНКЦЎРЬБт ЖЇЙЎРЬДй. БзЗЁМ inodeПЁ [ ]ИІ ОКПіМ ИЎНКЦЎЗЮ ИИЕщОюСи ШФ +ПЌЛъРкИІ
ОДДй.
inodedisp=[inode]+idisp
РЬЗИАд
ЧиМ ЦФРЯРЛ РаОюМ ГыЕхЙјШЃПЭ УГСќАЊ 6АГИІ ИЎНКЦЎЗЮ ЙДТ РлОїРЛ ЧпДй.
БзЗБЕЅ
РЬ ЧСЗЮБзЗЅРК ОЦСї ЙЬПЯМКРЬДй. ПжГФЧЯИщ forЙЎРИЗЮ ЧбСйОП КЏШЏЧб ДйРНПЁ УтЗТИИ ЧпСі КЏШЏЕШ АсАњИІ РњРхЧЯСі ОЪОвДй. ГЊСпПЁ АЊЕщРЛ КвЗЏПЭМ
НсИдРИЗСИщ АЂ СйРЛ РаОюМ КЏШЏЧб АсАњИІ ИЎНКЦЎЗЮ ИИЕщОюМ РњРхЧЯДТ АЭРЬ ЧЪПфЧЯДй.
|
f=open("d:/dev/python/result.txt", 'r')
result=f.readlines()
f.close()
nodedisps=[]
for iresult in result[1:]:
isplt=iresult.split()
inode=int(isplt[0])
idisp=list(map(float,isplt[1:]))
inodedisp=[inode]+idisp
nodedisps.append(inodedisp)
print(nodedisps)
|
readresult4.pyПЭ ДйИЅ АЭРК forЙЎ ОеПЁ nodedisps=[] Ањ forЙЎ ИЧ ИЖСіИЗПЁ nodedisps.append(inodedisp)АЁ УпАЁЕЧОњДй. БзИЎАэ УтЗТРК forЙЎ ЙлПЁМ УтЗТЧпДй.
append()
nodedisps=[]ДТ
Кѓ ИЎНКЦЎИІ СЄРЧЧб АЭРЬДй. БзИЎАэ appendДТ ИЎНКЦЎПЁ ИЎНКЦЎИІ УпАЁЧЯДТ ЧдМіДй. nodedispsЖѓДТ Кѓ ИЎНКЦЎПЁ inodedisp(ИЎНКЦЎДй)ИІ
appendЧЯДТ АЭРЬДй.
append()РЧ
ЛчПыЙ§РЛ pythonРЮХЭЧСИЎХЭЗЮ ШЎРЮЧиКИРк. ФкЕљРЛ ЧЯДйАЁ ХзНКЦЎИІ ЧиКМ ЖЇДТ РкНХРЬ ТЅАэ РжДТ ФкЕхЗЮ ХзНКЦЎЧиКИДТ АЭКИДй АЃДмЧЯАэ ИэШЎЧЯАд ХзНКЦЎЧиКИДТ
АЭРЬ ССДй.
|
>>> a=[]
>>>
a.append([1,2])
>>>
a
[[1, 2]]
|
aИІ
Кѓ ИЎНКЦЎЗЮ МГСЄЧЯАэ aПЁ append([1,2])ЗЮ [1,2]ИЎНКЦЎИІ appendЧпДй.
АсАњДТ
ИЎНКЦЎ ОШПЁ [1,2]ИЎНКЦЎАЁ УпАЁЕЧОњДй.
БзЗБДйРН
[2,4]ИЎНКЦЎИІ appendЧиКИРк. ХЋ ИЎНКЦЎОШПЁ РлРК ИЎНКЦЎ ЕЮАГАЁ ЕщОюАЁ РжДТ АЩ ШЎРЮЧв Мі РжДй.
|
>>> a.append([3,4])
>>>
a
[[1, 2], [3, 4]]
|
ДйНУ
ПьИЎ ФкЕхЗЮ ЕЙОЦПЭМЁІ forЙЎРЛ Дй ЕЙИщ ХЋ ИЎНКЦЎОШПЁ РаРК Сй Мі ИИХРЧ ИЎНКЦЎЕщРЬ УпАЁЕЩ АЭРЬДй. БзИЎАэ forЙЎ ЙлПЁМ РќУМ ИЎНКЦЎИІ УтЗТЧпДй.
НЧЧрАсАњДТ ОЦЗЁПЭ ААДй. ХЋ ИЎНКЦЎ ОШПЁ РлРК ИЎНКЦЎ 5АГАЁ ЕщОюРжДТ БИСЖДй.

РЬШФПЁ
ЕЮЙјТА ГыЕх(102)РЧ 3ЙјТА(UZ) КЏРЇАЊРЛ ОЫАэ НЭДйИщ nodedisps[1][2]ИІ РћПыЧЯИщ ЕШДй. ЛчНЧ РЬПЭ ААРЬ Ию ЙјТАЖѓДТ ЙцЙ§РИЗЮ
АЊРЛ ШЃУтЧЯДТ ЙцЙ§РК ЦФРЬНуРЧ БтДЩРЛ ШПРВРћРИЗЮ ЛчПыЧЯДТ ЙцЙ§РК ОЦДЯДй. pandasЖѓДТ И№ЕтРЧ dataframeРЛ РЬПыЧЯИщ ШЮОР НБАд ПјЧЯДТ
ГыЕхРЧ ПјЧЯДТ КЏРЇМККаРЛ ШЃУтЧв Мі РжДй. padasДТ ГЊСпПЁ ДйЗчБтЗЮ ЧЯАкДй.
СіБнБюСі
ЦФРЯРЛ РаОюМ НсИдРЛ Мі РжДТ М§РкЗЮ ЙйВйДТ РлОїРЛ ЧиКУДй. Бз АњСЄПЁМ split(), map(), strip(), append(), ИЎНКЦЎДѕЧЯБт(+)
ЕюРЛ ЛьЦьКУДй. ЦФРЯРЛ РаРИИщ ЙЎРкПЗЮ РаБт ЖЇЙЎПЁ БзАЭРЛ АЊРИЗЮ ЙйВйДТ АњСЄРЛ АХУФОп ЧбДй. РЬЙјПЁ ЛьЦьКЛ ФкЕхПЭ КёНСЧб ЦаХЯРИЗЮ СјЧрЕЧЙЧЗЮ
БтОяЧиЕб ЧЪПфАЁ РжДй.
ЧбАГРЧ АдНУЙАПЁ ПУИБ Мі РжДТ БлРЧ ОчРЬ СІЧбЕЧ РжОюМ ЦФРЯ ОВБтДТ ДйРН АдНУЙАЗЮ ПХАхНРДЯДй.



 0 Ка
0 Ка 44 Ка
44 Ка


